UNDERSTANDING WEBGL
My biggest issue with WebGL, and actually all non-immediate-mode OpenGL, is constantly fighting with the requirements of vertex buffers and attributes. I seem to be always looking for ways to minimise and optimise memory whereas vertex buffer objects always seem to want me to waste large amounts of it with duplicate attributes. However, reconciling that requirement in my own mind has actually given me a bit of insight into potentially alternate uses for the WebGL render pipeline.
Reconciling how best to utilise vertex buffer objects in OpenGL and WebGL didn’t come easy to me for some reason as it required almost a complete paradigm shift in my thinking. At its source, this was fundamentally a disagreement over implementation. In all my own modeling libraries and data structures, I use both face-based attributes and vertex attributes as most of the geometry I deal with day-to-day is facetted. There are the odd few curvaceous surfaces, but mostly it’s floors, walls, windows and doors made up of elements with flat, single-coloured faces usually seamed at 90 degrees to each other. Thus each face needs a normal and colour attribute and each vertex needs a position and texture coordinate attribute. Even then I store each attribute in a separate array and have normal and colour indexes in each face and position and texture coordinate indexes in each vertex so I don’t need to duplicate data.
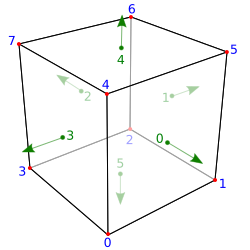
To better explain what I mean, let’s take the simplest possible example of the kind of geometry I’m talking about. A rectangular prism is comprised of 8 vertices and 6 faces, as shown in Figure 1.
How I Work
To render a rectangular prism with blue vertical and red horizontal surfaces, for example, I need to define and store eight (8) separate spatial positions, six (6) surface normals, two (2) colours and four (4) texture coordinates. Thus, for the minimum possible memory footprint and quickest transfer between CPU and GPU, I should really create a gl_Vertex attribute array with 8 unique XYZ positions, a gl_Normal attribute array with 6 unique IJK normal vectors, a gl_Color attribute array with the 2 RGBA colours and a gl_TexCoord attribute array with 4 unique UV texture coordinates. I would then draw these as GL_QUADS, referencing the attributes for each vertex using a gl_Index array with 24 integer quadruplets (one for each position, normal, colour and texture coordinate attribute), representing the 4 corners of each of the 6 faces.
The rectangular prism uses simple surface colours so really I don’t even need the texture coordinates. Also, I could probably draw the rectangular prism as a GL_TRIANGLE_STRIP with a couple of degenerate triangles to change direction around the faces and reduce the number of indexes to maybe 18 instead of 24 (GL_TRIANGLE_STRIP is the fastest way to render a mesh on some GPUs), but that would just complicate my argument unnecessarily.
So, let’s assume for the sake of argument that float, int and colour values are all 4 bytes in size, that XYZ positions and IJK normals use 3 floats each and UV texture coordinates use 2 floats. This means that the gl_Vertex array is 96 bytes (8×3×4), the gl_Normal array is 72 bytes (6×3×4), the gl_Color array is 8 bytes (2×4), the gl_TexCoord array is 32 bytes (4×2×4) and the gl_Index array is 384 bytes (24×4×4). This makes a total of 592 bytes for the rectangular prism.
This is obviously how I want to work and it’s how my libraries and JSON geometry file format works. However, it’s not how WebGL works or how a GPU is even able to work.
How WebGL Works
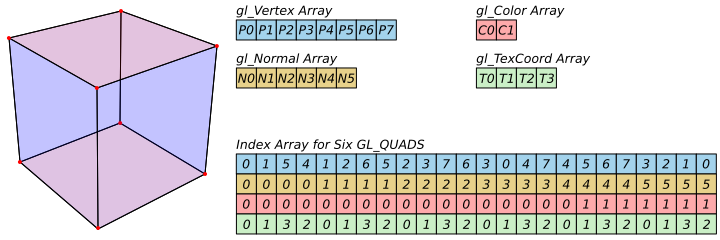
At the most basic level, all draw calls in WebGL can reference multiple vertex attribute arrays but only a single vertex index array. The draw call will invoke the vertex shader once for each entry in the vertex index array, sending it the attributes corresponding to that index within each attribute array. Thus, each of the gl_Vertex, gl_Normal, gl_Color and gl_TexCoord attribute arrays have to be exactly the same length and the four values at each corresponding array index need to apply to the same vertex. This means that, even though only a single attribute might vary, you need to duplicate all other attributes into each array in order to form a new vertex.
In the case of a rectangular prism, every vertex in each of the 6 faces is unique because, even though they might share the same position and texture coordinate, the normal will always be different and also possibly the colour. The result is that you actually need to store 24 separate attributes in each attribute array, one for each entry in the index list, as shown in Figure 3.

This means that the gl_Vertex array needs to be 288 bytes (24×3×4), the gl_Normal array needs to be 288 bytes (24×3×4), the gl_Color array needs to be 96 bytes (24×4), the gl_TexCoord array needs to be 192 bytes (24×2×4) and the gl_Index array needs to be 96 bytes (24×4). This makes a total of 960 bytes for the rectangular prism. You could probably cut that to 864 bytes by ordering the attributes correctly and using a draw call that doesn’t need vertex indexes.
This is true even if you use a single array with interleaved values. This basically means arranging the attributes sequentially within a single array, as shown in Figure 4, and setting the stride values so OpenGL knows how to separate them.

How it Should Have Worked
Having to do this really hurts as there is so much seemingly unnecessary duplication, as well as the nagging doubt that there has to be a better way. The rectangular prism example I used earlier is fairly trivial, but I’m sure you could imagine the potential memory savings and CPU/GPU transfer optimisation in a large and complex rectilinear building model where most of the floor, wall and ceiling corners all line up and tens of thousands of surfaces could potentially share the same surface normals or colour attributes.
I just can’t help constantly questioning how difficult it really would have been to have let the GPU process vertex indices as int4 instead of just int. After all, attributes can be vec4, vec3 or vec2. This way each vertex could have separate indexes into each of the position, normal, colour and texture coordinate arrays and these arrays could then be so much smaller. The draw calls would still work in exactly the same way, they would just fetch the appropriate attributes using the four separate indexes in an int4. This may require some array padding if you want to interleave attributes in a single array, but it could still work in virtually the same way.
Reconciling
However, over time you give in you realise that you can’t fight the hardware. This is where the required paradigm shift comes in. Previously I was creating arbitrary groupings of attributes and giving them some sort of hierarchy. For example, the rectangular prism has 8 corners so I would think of it as having 8 vertices. The question is, why was I giving some sort of priority to spatial position. Surely the I, J and K components of the normal are just as important and just as defining as the X, Y and Z components of position. The same is true of colour and texture. Thus, you really need to think of a vertex as multi-dimensional with each attribute component adding another dimension.
Whilst this makes sense, it still wastes memory. However it does so by trading it for increased speed. I still get a pang each time I have to ‘inflate’ my data and I haven’t completely given up the fight. In the back of my mind I still think there might be some convoluted way to use multiple indexes per vertex by storing arrays of unique normal, texture and colour values as uniforms and using the built-in gl_VertexID variable with some kind of run-length encoded index transform array as another uniform. However time and good sense has not yet permitted me to investigate this.
Alternate Uses for a GPU
One really interesting side effect of thinking about a vertex as arbitrarily dimensional is that you can start to imagine a vertex that doesn’t even have a position at all. Sure, most of the shader code framework is designed to convert 3D model positions to 2D canvas coordinates, but you don’t have to use it that way. If you think of vertex attributes as an arbitrary dataset, then it’s easier to imagine ways of using the GPU as a very fast and highly parallel data processor.
The major limitation here is that you have to be able to process each element of the dataset entirely separately. You can use outside information sent in as uniforms but, just as you can’t reference attributes from another vertex within the vertex shader, you won’t be able to reference other elements at different indexes within the dataset. It’s a limitation, but it still opens up a huge range of possibilities.
For example, one of the major hurdles in my annual incident solar radiation calculations has been the extremely long and involved process of solving the Perez sky illuminance distribution for each hour of the year. Currently this takes about 11 seconds using all 8 threads on a quad-core i7 processor. Using direct/diffuse solar radiation, Sun azimuth/altitude and date/time as vertex attributes, each time step can be processed entirely independently and in parallel on the GPU by a vertex shader. Doing this means that even sub-hourly time steps are now lightning fast as the NVIDIA GeForce GT 650M on my laptop distributes the calculations over 384 parallel processing units instead of just 8 threads.
In my particular use case, the annual sky illuminance is only generated once at the start of a longer calculation that is invoked from a dialog box. Thus, when the OK button is pressed to start the calculation, there is no model redraw required so the GPU is essentially idle at that time anyway. It’s a completely free resource that is available on all devices (desktops, laptops, tablets and phones), so why not use it.
GP-GPU in WebGL?
There are some really amazing things happening in the world of general-purpose computing using graphics processing units ( GPGPU ) on the desktop and in OpenGL 4, such as OpenCL , CUDA , Shader Storage Buffer Objects ( SSBO ) and compute shaders . However, JavaScript and WebGL provide no such tools or extensions at the moment, so everyone has to work out their own low level hack if they want to achieve anything similar. WebCL looks very interesting, but that is still a long way from having good browser support.
Without compute shaders, you have to steal time from the GPU between renders and manage that appropriately yourself. Without a writable SSBO, the only way to pass data back from the GPU is via an image rendered by the fragment shader. I use the GPU to render a texture 365x288 in size (365 days of the year in 5 minute increments over each day) and then have to decode floating point results back from the RGBA values at each pixel. I have tried using a floating point texture, which is a bit easier but there is just too much risk that devices that might use my apps won’t support the required OES_texture_float extension.
The biggest challenge in my own low level hack is accurately transferring calculated values between the vertex shader and the fragment shader to actually generate the texture image. It is relatively easy to abstract the vertex shader, but the fragment shader’s job is to interpolate data from the vertex shader into pixels in a frame buffer. Managing that interpolation to maintain high level accuracy is the real core of this hack, and I’m not fully confident that I’ve mastered it yet. The new WebGL 2.0 spec promises to include transform feedback , which appears to allow direct access to calculated results sent back from the vertex shader without having to pass through the fragment shader. If this turns out to be the case, then that will solve a lot of my problems with this calculation and opens up a whole world of other applications for me.
A few browsers are starting to experiment with some of this stuff as extensions to WebGL 1.0, so I look forward to being able to play around a bit. Otherwise it’s probably a good couple of years before WebGL 2.0 is fully implemented and available everywhere, so I better get back to hacking away.
Update 18 Dec, 2015
I have recently discovered an amazing tool called
WebCLGL
which effectively emulates OpenCL using WebGL shaders. It allows you to create operations using an OpenCL coding style and then prepares all the input/output as floating point texture buffers and interprets the code into GLSL shaders. It obviously has some of the core limitations I was trying to avoid, requiring hardware support for the OES_texture_float and OES_texture_float_linear extensions, but at least it lets me experiment with some of this new technology right now.